eBay が OpenTelemetry に転換した理由とその方法
Blog posts are not updated after publication. This post is more than a year old, so its content may be outdated, and some links may be invalid. Cross-verify any information before relying on it.
eBay は、オブザーバビリティの業界標準により適切に整合するために、OpenTelemetry への重要な転換を行いました。

はじめに
オブザーバビリティは、あらゆる組織にとっての目と耳を提供します。 オブザーバビリティの大きな利点は、顧客体験に影響を与える可能性のある重要なワークフローにおける進行中の問題を効率的に浮き彫りにし、収益の損失を防ぐことにあります。 オブザーバビリティの状況は常に変化しており、OpenTelemetry の世界における最近の動向により、私たちは戦略を見直し、OpenTelemetry への転換を余儀なくされました。 eBay のオブザーバビリティプラットフォーム Sherlock.io は、開発者とサイトリライアビリティエンジニア(SRE)に対して、eBay エコシステムを支えるさまざまなアプリケーションを観測するための堅牢なクラウドネイティブツール群を提供しています。 Sherlock.io はオブザーバビリティの 3 本柱であるメトリクス、ログ、トレースをサポートしています。 プラットフォームのメトリクスストアは、Prometheus ストレージエンジンのクラスター化されたシャード実装です。 私たちは Metricbeat エージェントを使用して毎分約 150 万の Prometheus エンドポイントをスクレイプし、メトリクスストアに取り込んでいます。 これらのエンドポイントとレコーディングルールにより、毎秒約 4,000 万サンプルが取り込まれます。 取り込まれたサンプルは、Prometheus 上に 30 億のアクティブ時系列として格納されています。 このように、eBay のオブザーバビリティプラットフォームは非常に大規模に運用されており、それに伴い新たな課題が生じています。
オブザーバビリティプラットフォームプロバイダーとして、eBay はメトリクスエンドポイントのスクレイプやログファイルのテーリングにエージェントを使用した最初の企業の一つでした。 以前のブログ記事で説明したように、私たちはプラットフォームへのシグナルの取り込みに Elastic Beats を大いに活用してきました。 Beats は、メトリクスやログなどの運用データを軽量に転送するツールです。 2016 年から 2020 年までの 5 年間、私たちはすべての Kubernetes クラスター上で Filebeat と Metricbeat の両方を DaemonSet として実行しました。 DaemonSet を使うと、Kubernetes クラスターのすべてのノードに特定のワークロードをデプロイできます。 しかし、社内ハックウィーク中に行った実験により驚くべき結論が得られ、DaemonSet の使用を再検討することになりました。 このブログ記事では、特にメトリクススクレイピングに関して直面した問題と、独自のソリューションをどのように進化させたかについて説明します。 また、ライセンスに関する変化するオープンソースの状況にどのように対応してきたか、そして OpenTelemetry とどのように整合していく計画かについても詳しく説明します。
メトリクスの計装
eBay におけるメトリクスの計装は、Prometheus エンドポイントにほぼ標準化されています。 さまざまなアプリケーションのエンドポイントは、以下のようなさまざまな計装手法によって公開されています(これらに限定されません)。
- 公式 Prometheus クライアント(Java、Go、Python などを含む)
- Micrometer
- Prometheus エクスポーター付き OTel SDK
- リクエストに応じて Prometheus エンドポイントを出力するカスタムコード
eBay のプラットフォームエンジニアリンググループが提供するフレームワークには、計装クライアントが組み込まれており、サーバーサイド、クライアントサイド、DB クライアントのメトリクスを表すさまざまなメトリクスエンドポイントも公開されています。 アプリケーションの性質に応じて、スクレイプが必要な Prometheus エンドポイントを公開できます。 アプリケーションオーナーは、ビジネス KPI を計装するための独自のエンドポイントを公開することもできます。
Autodiscover
eBay エコシステムを支えるアプリケーションの大部分は、eBay の社内 Kubernetes プロバイダーである Tess 上で稼働しています。 eBay は Tess を基盤とする数百の Kubernetes クラスターを運用しており、アプリケーションはそれらのクラスターの任意の数と組み合わせで実行できます。 アプリケーションオーナーは、フレームワークレベルの計装から自由に利用できるメトリクスとともに、自分のアプリケーションメトリクスをオンボードすることを選択できます。 私たちのエージェントは、現在実行中の Kubernetes Pod がどのエンドポイントを公開しているかを正確に把握する必要があります。 エージェントにこの情報を提供するために、私たちは Beats プラットフォームに「ヒントベースの Autodiscover」と呼ばれるタスクを実行できるよう機能を拡充しました。 Autodiscover は Beats の構成要素で、Kubernetes API サーバーのような動的なソースから以下のような情報をエージェントに配信できます。
- スクレイプが必要なエンドポイントは何か
- Dropwizard、Prometheus、Foobar、その他のどの種類のエンドポイントか
- どのくらいの頻度でスクレイプすべきか
- SSL 証明書のような、エージェントが知っておくべき追加情報はあるか
より複雑なディスカバリパターンが必要になるにつれ、私たちは Beats オープンソースコミュニティと協力して、特定のニーズに合わせて Autodiscover の機能を強化しました。 私たちが貢献した機能には以下のものがあります。
- 複数の設定セットのディスカバリ: 従来のアノテーションベースのスクレイピングは、スクレイプマネージャーのターゲットに対してシンプルな設定しか提供できないという制限がありました。 各エンドポイントがさまざまな処理やスクレイプ間隔といった動的なニーズを持つことを踏まえ、私たちは Autodiscover を拡張して複数の設定セットを受け入れられるようにしました。
- 名前空間のアノテーションからのターゲットディスカバリ: スクレイプターゲットを宣言するための規定の方法は、Pod spec にアノテーションを追加することでした。 しかし、そこに追加すると変更により Pod の再起動が発生します。 フレームワーク上で計装されているメトリクスに対する変更で、すべてのデプロイ済みアプリケーションで利用可能な場合、これは望ましくありません。 すべての Pod の再起動を避けるために、名前空間レベルのアノテーションも参照するように Autodiscover のサポートを追加しました。
これらの機能により、Beats Autodiscover は Kubernetes クラスター上にデプロイされたターゲットを特定するための、最も多機能で豊富なディスカバリメカニズムの一つとなっています。
DaemonSet によるメトリクススクレイピングの制限
大規模に Metricbeat を実行するための最初の試みは、すべての Kubernetes クラスター上で DaemonSet として実行することでした。 各 Pod には、そのノードで公開されるすべてのメトリクスを処理するために 1 CPU と 1GB のメモリが割り当てられました。 Metricbeat が起動すると、API サーバーにそのクラスターのすべての名前空間と、自身が動作するノードにデプロイされた Pod を要求します。 この情報をもとに、各 Pod について、Pod とその Pod の名前空間のアノテーションを照合して設定を作成します。 結果として観察されたことには以下のものがあります。
- リソースの断片化:N ノードクラスターで N 個の Beats を実行する場合、1 つの Beat パイプラインのブートストラップコストが 50MB だとすると、50*N MB のリソースが無駄になります。 3000 ノードの Kubernetes クラスターでは 150GB にもなります。
- 大きなエンドポイントのポーリング時の OOM 問題:1 エンドポイントあたり 150,000 エントリもの大きさのエンドポイントを公開する利用者を確認しています。 「kube-state-metrics」のような巨大なエンドポイントは 300 万エントリに達し、1 回のポーリングで 600MB のデータを生成します。 このようなユースケースがノードに集中すると、スクレイピングの信頼性が低下します。
以下の図は、Metricbeat、Filebeat、Auditbeat などの Beats インスタンスが DaemonSet としてデプロイされた場合に、Sherlock.io プラットフォームとどのようにインターフェイスするかを示しています。
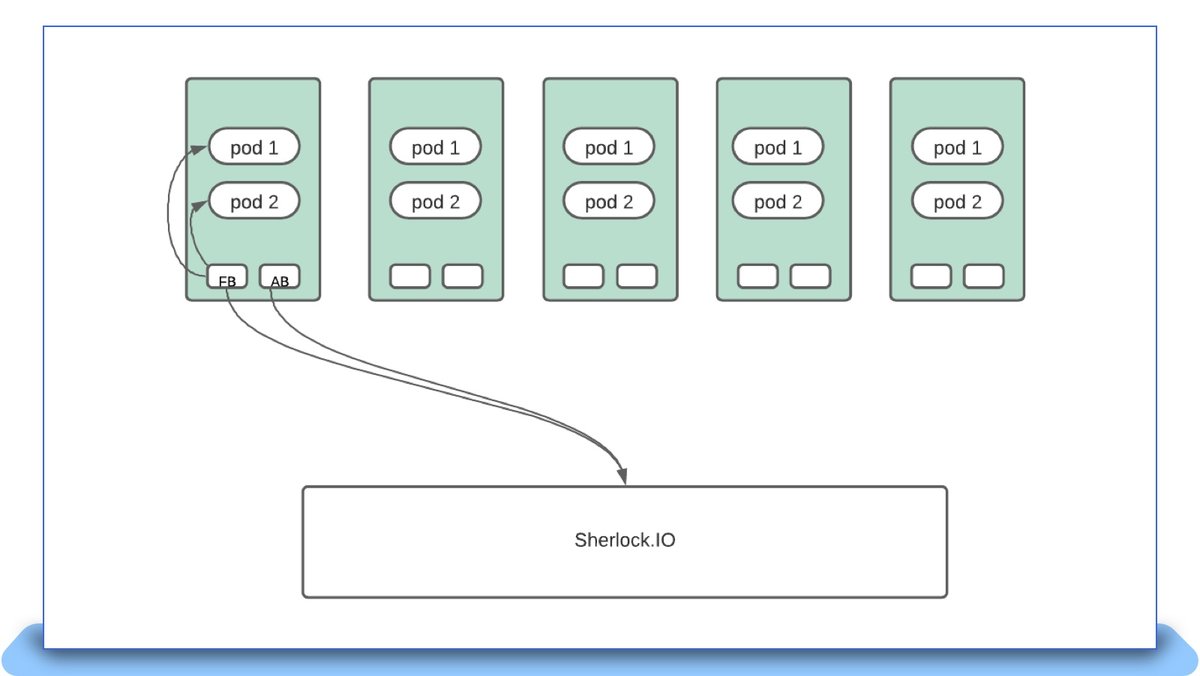
クラスターローカルスクレイプへの移行
別のプロジェクトでの作業中に、クラスター全体のすべてのターゲットに対して Metricbeat を単一インスタンスとして実行するというショートカットを取りました。 Metricbeat の実行に必要な CPU とメモリの合計使用量を観察したところ、結果は驚くべきものでした。 デプロイ中に以下のことが判明しました。
- Kubernetes ノード数:2851
- CPU 使用量:29 コア
- メモリ使用量:57GB
- 取り込みレート:毎秒 238K サンプル
- ノードあたりの監視エンドポイント数:4
- 監視ノードあたりの平均メモリ使用量:20MB
- 監視ノードあたりの平均 CPU 使用量:0.01 コア
DaemonSet モードでノード上の同等のエンドポイントを監視する単一の Metricbeat インスタンスは、約 200MB(10 倍)と約 0.6 コア(60 倍)を消費していました。 クラスター全体では 570GB と約 1700 CPU に達します。 クラスターローカルインスタンスへの移行による全体的なコスト削減は約 90% でした。
この結果を受けて、スクレイプの処理方法を根本的に見直すことになりました。 クラスター全体に対して単一インスタンスを実行する場合、そのインスタンスがアップグレードや障害を経験すると、その時点で 100% のスクレイプがダウンすることになります。 障害の影響を軽減するために、Metricbeat を N レプリカの StatefulSet としてデプロイしました。 Pod のリスト全体は Metricbeat インスタンスの数に基づいて N 分割にシャーディングされ、各インスタンスは割り当てられたシャードを監視します。
xxHash(pod uid) % statefulset_size == instance number
各インスタンスは API サーバーに対してフルスキャンを行いますが、自身が監視するべきもの以外はすべて無視します。 このモデルは Metricbeat に適しています。 主に Prometheus エンドポイントをスクレイプするため、このアクティビティは Tess ノードの外部で実行できるからです。 3000 ノードの大規模な Kubernetes クラスターでは、最大 30 インスタンスとなり、より多くの CPU とメモリが割り当てられるため、ノード上のデーモンとして実行する場合よりも大幅に大きなエンドポイントをスクレイプできます。 1 つの Metricbeat インスタンスが再起動した場合、スクレイピングの中断はそのインスタンスのみが監視するエンドポイントに限られ、障害の割合はインスタンス総数の 1/N に削減されます。
新しいデプロイメントパターンは以下のように可視化できます。
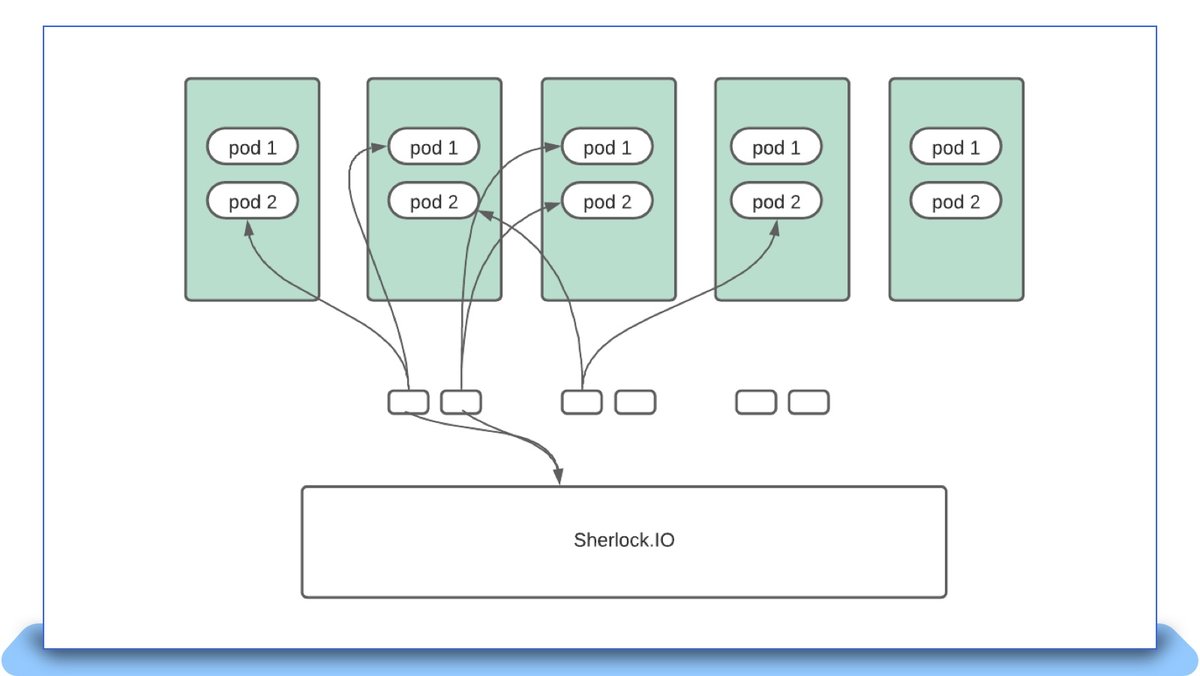
Autodiscover の分離
クラスターローカルスクレイプへの移行により、DaemonSet 使用時よりも大幅にスケールアップできましたが、このモデルにはまだ改善の余地がありました。 特に Pod 密度の高い大規模クラスターで、新たな問題が発生しました。 すべての Metricbeat インスタンスがすべての Pod をスキャンして自身が監視すべきものを選択する必要があるため、クラスター内の Pod 数によっては初回スキャンに非常に長い時間がかかることがあります。 ロールアウト時、新しい Metricbeat Pod がスクレイプを再開するまでに最大 10 分かかることがあり、非常に問題になりました。 インスタンス数によっては、Metricbeat がリクエストするさまざまなリソースに対する WATCH の数により、API サーバーに過度な負荷がかかることもありました。
さらなる評価の後、Autodiscover をエージェントから切り離し、独自の制御ループに移動することにしました。 この制御ループは以下を実行します。
- Beats の Autodiscover ロジックと同様のパーサーを実装する
- スクレイピング作業を実行できるすべてのエージェントを発見する
- これらのエージェントの 1 つを選択する
- 選択されたエージェントにターゲットを監視するための設定を渡す
制御ループは、エージェントのクラッシュ、エージェントの過剰割り当て、その他の障害シナリオにおいてワークロードを再配分するなど、重要な判断を行います。 アノテーションを解析するロジックがエージェントから分離されたため、Beats が公開する機能と新しいエージェント間のマッピングが存在する限り、任意のエージェント用の設定を簡単に生成できます。
OpenTelemetry の登場
2019 年、OpenTracing と OpenCensus のコミュニティが合流し、OpenTelemetry が誕生しました。 OpenTelemetry の取り組みは、任意のオブザーバビリティバックエンドにデータを取り込み、変換し、送信するためのベンダー非依存の API、SDK、ツールを提供することを目標として開始されました。 このような取り組みへの投資は、コンテナをクラウド上で管理するためのベンダー非依存の API を提供する Kubernetes を選択した eBay にとって、オープンソースの活用方法と自然に合致するものでした。 2021 年、私たちは分散トレーシングの実験を開始し、開発者にとってどのように役立つかを検討しました。
当時、OpenTelemetry Collector のコードベースを見て、メトリクス、ログ、トレースの定義済み型や、OpenMetrics エンドポイントからメトリクスを収集するための Prometheus スクレイプマネージャーの使用など、いくつかの機能に大きな可能性を見出しました。 私たちは分散トレーシングの導入に、OpenTelemetry Collector と OpenTelemetry SDK を選択しました。 当然ながら、メトリクスとログの収集も OpenTelemetry Collector に移行する方法を検討する必要がありました。 すべての機能ギャップを埋め、新しいオープンソースコミュニティとの関係を構築し、ダウンタイムなしで大規模なメトリクス収集インフラストラクチャを入れ替える必要があるため、これは容易な取り組みではありません。 2022 年の初めに、メトリクススクレイピングを OpenTelemetry Collector に移行する困難な作業に着手しました。
移行
ディスカバリロジックをエージェントから分離していたため、実際の移行は OpenTelemetry Collector が理解できる設定を生成するだけで済みました。 これらの設定は、新しい Pod がスピンアップするたびにプッシュされ、その Pod が終了するとクリーンアップされる必要がありました。 しかし、OpenTelemetry Collector には重要なギャップがありました。 設定を動的にリロードできないのです。 OpenTelemetry Collector にはメトリクスの受信、処理、エクスポートの方法を定義する「パイプライン」という概念があります。 パイプラインの動的リロードを実現するために、部分的なパイプラインを記述するファイルで構成されるディレクトリを監視できる「filereloadreceiver」を考案しました。 これらの部分パイプラインは Collector の全体的なパイプラインにプラグインされます。 メトリクススクレイピングが必要な各 Pod には、Autodiscover コントローラーが生成して Collector にプッシュする部分パイプラインがあります。 このプロセスにおけるもう一つの複雑な作業は、Beats プラットフォームで使用していたすべての機能と OpenTelemetry Collector 間のマッピングテーブルの作成でした。 たとえば、Beats のフィールドは OpenTelemetry の attribute プロセッサーの使用に対応します。 このようなマッピングと filereloadreceiver を用意したことで、以下のように OpenTelemetry Collector 用の新しい設定を生成できるようになりました。
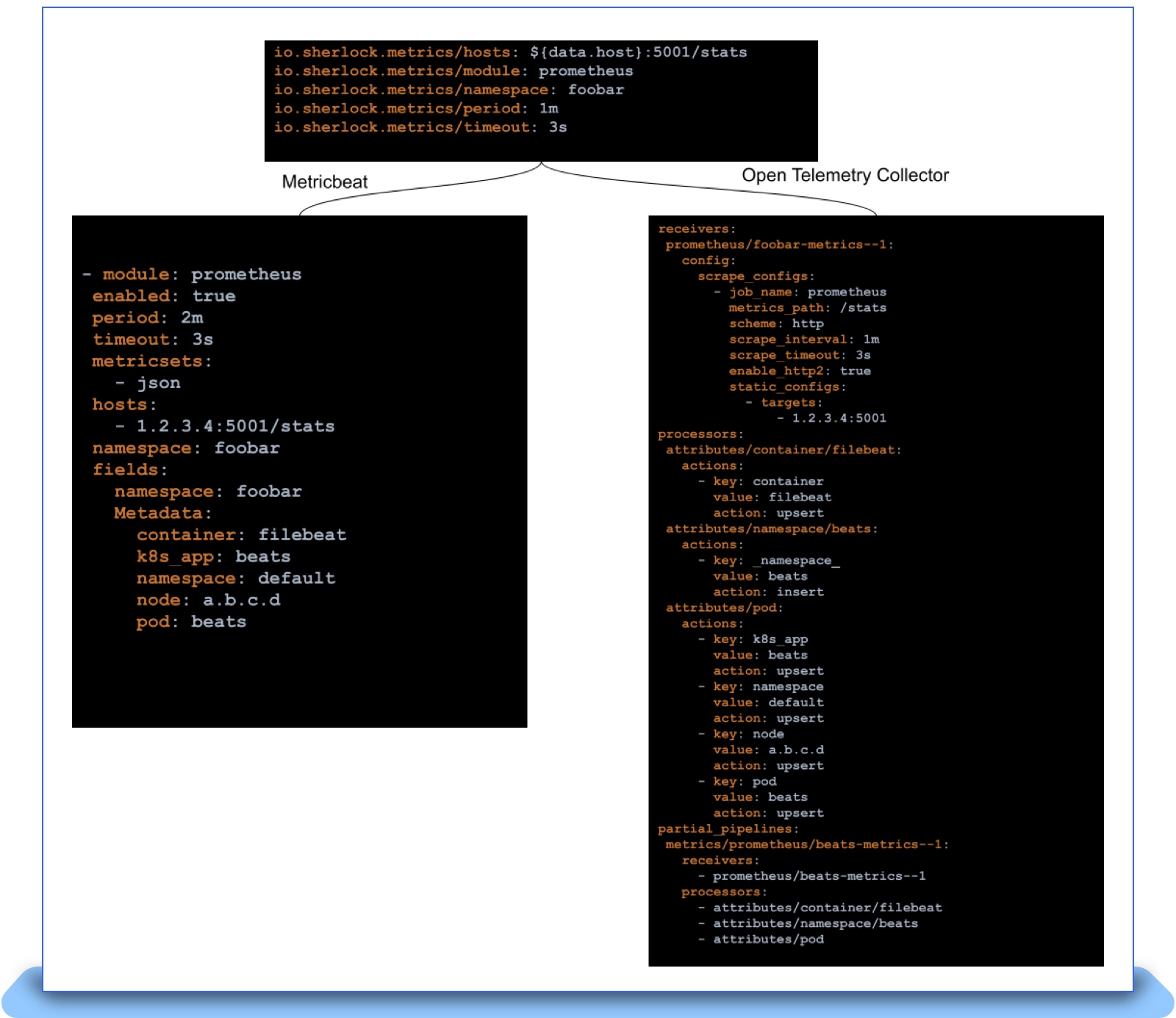
上図のように、Pod/名前空間のアノテーションというエンドユーザーとの契約はそのままに、内部のエージェントのみを入れ替えることができました。 これにより、新しいエージェントのロールアウト作業が大幅に簡素化されました。 最後の障害は、Elastic Beats、OpenTelemetry、そして時には Prometheus スクレイプマネージャー間のセマンティクスの不一致でした。 本番環境の Metricbeat をすべて置き換えられるようになるまで、ここに数カ月を費やしました。 私たちが発見し、OpenTelemetry Collector プロジェクトでパッチを支援した不一致には以下のものがあります。
- 「_」で始まるラベルとメトリクス名のサニタイズを Prometheus と整合させる
- ラベルのサニタイズを無効にする機能
- 「:」で始まるメトリクス名を正しく処理する
- 正規表現を使用した Pod ラベルの抽出機能
これらの問題は発見が困難で、Kubernetes クラスターを OpenTelemetry Collector に移行しようとした際に初めて表面化することもありました。 このような問題に遭遇すると、ロールバックが唯一の選択肢となり、振り出しに戻ることを余儀なくされました。 一つの部分的な解決策として、Metricbeat と OpenTelemetry Collector の両方を使用してエンドポイントをスクレイプし、同時にメトリクスストアに取り込み、メトリクス名とラベルを比較してスクレイプが同等であることを確認する比較スクリプトの作成がありました。 これにより、前に進む確信が大幅に高まりました。
前に進むことは、特定の機能のサポートを打ち切ることを意味する場合もあります。 Dropwizard メトリクスのサポートについてはまさにそうであり、ユーザーに移行を促しました。 セマンティクスの違い以外にも、Exemplar のサポートなど、プロジェクトにとって重要と考える機能の追加にも積極的に取り組んでいます。
数カ月にわたるハードワークとコミュニティからのサポートを経て、Metricbeat を完全に廃止し OpenTelemetry Collector に置き換えたことを発表できることを嬉しく思います。 現在、Filebeat についても同様の作業を進めており、初期のパフォーマンスベンチマークは非常に有望です。 これまでに 10 件以上のコントリビューションを行いましたが、これは非常に実りあるコラボレーションの始まりに過ぎません。
まとめ
過去 5 年間で、eBay は従来の常識を見直す必要に迫られるいくつかの需要の急増に直面しました。 DaemonSet から始め、大規模ではコストが高く信頼性が低いことがわかりました。 クラスターローカルモデルに移行してエージェントのコストを約 90% 削減しましたが、API サーバーとエージェント自体で行われる作業に冗長性がありました。 ディスカバリを分離して、スケジューリングを実行する制御ループに移行し、エージェントをスクレイプターゲットを受け入れられるステートレスなプロセスにしました。 OpenTelemetry の成熟度の向上を踏まえ、メトリクスに OpenTelemetry Collector を採用し、ログについても同様の作業を積極的に進めています。 私たちは大規模なエージェント運用から学び続け、必要に応じて方向転換を続けます。 OpenTelemetry コミュニティがオブザーバビリティエコシステム内の標準化への道を切り開く中、私たちは引き続きコミュニティと協力していきます。 OpenTelemetry を使用することで、テレメトリーを Sherlock.io に送信するための業界承認のオープンスタンダードを開発者に提供できるようになりました。 プロファイリングなどの新しい機能のサポートがコミュニティで進むにつれ、開発者コミュニティに利益をもたらすためにプラットフォームに採用していきます。
クレジット
これらの最適化や方向転換の多くは、以下の活動に関わった多くのソートリーダーなしには実現できませんでした。
私たちは、世界クラスのオブザーバビリティソリューションを eBay の開発者コミュニティに提供するべく尽力する中で、過去の Elastic Beats コミュニティと現在の OpenTelemetry コミュニティの両方からのサポートと協力に非常に感謝しています。
Elastic コミュニティ:
- Monica Sarbu
- Tudor Golubenco
- Nicolas Ruflin
- Steffen Siering
- Carlos Pérez-Aradros
- Andrew Kroh
- Christos Markou
- Jaime Soriano Pastor
OpenTelemetry Collector コミュニティ:
この記事は eBay Tech Blog に最初に投稿されたものです。