Mastodon が本番環境で OpenTelemetry Collector を運用する方法
2025年初頭、OpenTelemetry Developer Experience SIG は最初のコミュニティサーベイの結果を公開しました。 最も強いテーマの一つは明確でした。チームは OpenTelemetry SDK や OpenTelemetry Collector が実際に本番環境でどのように使われているかについて、より多くの実例を求めていたのです。
このギャップを埋めるために、SIG はさまざまな業界、アーキテクチャ、企業規模のエンドユーザーから直接ストーリーを収集し始めました。 この記事は、組織の実際の運用事例に特化した新しいシリーズの第一弾です。 小規模ながらも独自の課題を持つケースからスタートします。
最初のストーリーの主役は、世界規模で運営しながらも驚くほど少人数のチームで活動している非営利団体 Mastodon です。
Mastodon の概要
Mastodon は、非営利団体が運営する、フリーでオープンソースの分散型ソーシャルメディアプラットフォームです。
分散化はここではマーケティング用語ではなく、中核的なアーキテクチャ原則です。 誰でも自分の Mastodon サーバーを運用でき、それぞれ独立して運営されるサーバーは、Fediverse(ActivityPub などの標準化されたプロトコルを使用して相互に通信する独立したソーシャルプラットフォームの連合ネットワーク)の一部として、オープンプロトコルを使って相互運用します。 メールと同様に、ユーザーは誰がサーバーを運営しているかに関係なく、インスタンス間で通信できます。
この思想は、Mastodon の機能に関する意思決定だけでなく、オブザーバビリティへのアプローチにも影響を与えています。
組織構造
Mastodon の組織全体は約 20 名で構成されており、オブザーバビリティインフラストラクチャ(OpenTelemetry Collector を含む)はたった一人のエンジニアが管理しています。
少人数のチームにもかかわらず、Mastodon は 2 つの大規模な本番 Mastodon インスタンスを運用しています。
9~15 ノード(各 16 コア、64 GB RAM)間でオートスケーリングする Kubernetes 上で稼働しています。 Web フロントエンドは 5~20 Pod、さまざまな Sidekiq ワーカープールは 10~40 Pod の間でスケーリングします。 平均して、mastodon.social では常時 70~80 の Pod が稼働しています。 このプラットフォームは 1 日あたり最大 30 万のアクティブユーザー を処理し、毎分約 1,000 万リクエストをさばいています。
3~6 ノード(各 8 コア、32 GB RAM)間でオートスケーリングする Kubernetes 上で稼働しています。 Web フロントエンドは 3~10 Pod、Sidekiq プールは 5~15 Pod の間でスケーリングし、合計で平均 20~30 Pod が稼働しています。 このインスタンスは、小規模ながらも依然としてかなりの規模で運用されています。
運用帯域が限られているため、シンプルさと信頼性は譲れない条件です。
OpenTelemetry の導入: 設計による選択の自由
Mastodon はオープンソースであり、他者が運用できるように設計されているため、チームはオペレーターの自由を保つテレメトリーソリューションを求めていました。
OpenTelemetry がデフォルトになったのは、各 Mastodon サーバーオペレーターがテレメトリーをどのように、あるいは収集するかどうかを自分で決められるからです。
シンプルな環境変数による設定を使用して、オペレーターは以下のいずれかを選択できます。
- テレメトリーをオブザーバビリティバックエンドに直接送信する(Ruby SDK の設定のみを使用)
- テレメトリーを OpenTelemetry Collector 経由でルーティングする
- テレメトリーを完全に無効にする
Mastodon のコア組織は、外部インスタンスがどのようにオブザーバビリティを扱っているかを追跡していません。 重要なのは、発行されるテレメトリーが OpenTelemetry セマンティック規約 に厳密に準拠しており、どこでも利用できることです。
このアプローチにより、ベンダー固有のデータモデルが回避され、Mastodon が独自の規約を維持することなく、より広い OpenTelemetry エコシステムとの互換性が確保されます。
Collector アーキテクチャ: ネームスペースごとに1つだけ
Mastodon の Collector アーキテクチャは意図的に最小限です。
Kubernetes ネームスペースごとに1つの OpenTelemetry Collector がすべてのテレメトリーシグナル(トレース、メトリクス、ログ)を処理します。 ゲートウェイとエージェントの別階層も、複雑なルーティングレイヤーも、カスタムデプロイメントツールもありません。
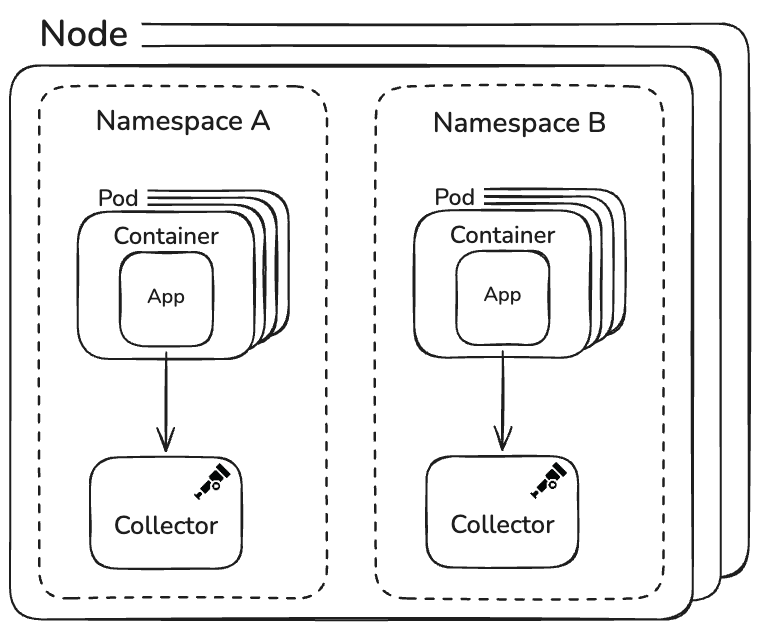
この規模とトラフィック量で、これは十分すぎるほどの実績があります。
インタビューでは、Mastodon のソフトウェアエンジニアである Tim Campbell が、Collector を運用してきた約2年間で 一度も問題が発生していない と語りました。
「驚いたことに、しかも本当にうれしい驚きだったのですが、これまで一度も問題にぶつかっていません。 これには Kubernetes のオペレーターを使っているので、仮に何か問題が起きても自動的に再起動されます。 少なくとも Datadog 上で実際のトレースやログを見る限り、欠落は見当たりません。 メモリー使用量やプロセスの面でも、設定した制限の範囲内でまったく問題なく安定しています。」
デプロイメントとライフサイクル管理
運用上のオーバーヘッドを可能な限り低く抑えるために、Mastodon は以下を利用しています。
- Kubernetes 向けの OpenTelemetry Operator
- Git ベースのデプロイメントとプロモーションのための Argo CD
各 Collector は OpenTelemetryCollector カスタムリソースとして定義されます。
そこから、Kubernetes がリコンシリエーション、再起動、ライフサイクル管理を自動的に処理します。
「要するに、必要な OpenTelemetryCollector オブジェクトごとに YAML ファイルを 1 つ作ればよくて、あとは Argo が必要なデプロイや更新を自動で行ってくれます。」
このモデルが提供するもの:
- 宣言的な設定
- 障害時の自動復旧
- Git 履歴による明確な監査可能性
注目すべきことに、Mastodon は Collector Pod に厳密な CPU やメモリの制限を強制していません。 実際には、リソース消費量はプラットフォームの他の部分と比較して無視できる程度に留まっています。
サンプリングによるトラフィック管理
リソース制限に頼るかわりに、Mastodon は主にテイルベースサンプリングによってオブザーバビリティのオーバーヘッドを制御しています。
- mastodon.social では、成功したトレースは約 0.1% でサンプリングされ、極めて高いトラフィックにもかかわらず、1分あたり数十件のトレースしか生成されません。
- mastodon.online では、サンプリングはやや寛容ですが、同じ原則に従っています。
- エラートレースはすべて常に収集され、障害に対する完全な可視性が確保されます。
このアプローチにより、価値の高い診断データを保持しつつ、データ量を予測可能に保てます。
設定: 独自の方針はあるが最小限
Mastodon は OpenTelemetry Collector Contrib ディストリビューションを使用しています。 これは主に利便性のためで、カスタムビルドを必要とせず、必要なものがすべて含まれています。
設定の焦点は以下のとおりです。
- すべてのシグナルの OTLP インジェスト
- Kubernetes メタデータのエンリッチメント
- リソース検出
- テイルベースサンプリング
- バックエンド互換性のための変換
以下に本番設定の全体を参考として掲載します(otelbin でも確認できます)。
apiVersion: opentelemetry.io/v1beta1
kind: OpenTelemetryCollector
metadata:
name: mastodon-social
namespace: mastodon-social
spec:
nodeSelector:
joinmastodon.org/property: mastodon.social
env:
- name: DD_API_KEY
valueFrom:
secretKeyRef:
name: datadog-secret
key: api-key
- name: DD_SITE
valueFrom:
secretKeyRef:
name: datadog-secret
key: site
config:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
cors:
allowed_origins:
- 'http://*'
- 'https://*'
processors:
batch: {}
resource:
attributes:
- key: deployment.environment.name
value: 'production'
action: upsert
- key: property
value: 'mastodon.social'
action: upsert
- key: git.commit.sha
from_attribute: vcs.repository.ref.revision
action: insert
- key: git.repository_url
from_attribute: vcs.repository.url.full
action: insert
k8sattributes:
auth_type: 'serviceAccount'
passthrough: false
extract:
metadata:
- k8s.namespace.name
- k8s.pod.name
- k8s.pod.start_time
- k8s.pod.uid
- k8s.deployment.name
- k8s.node.name
labels:
- tag_name: app.label.component
key: app.kubernetes.io/component
from: pod
pod_association:
- sources:
- from: resource_attribute
name: k8s.pod.ip
- sources:
- from: resource_attribute
name: k8s.pod.uid
- sources:
- from: connection
resourcedetection:
detectors: [system]
system:
resource_attributes:
os.description:
enabled: true
host.arch:
enabled: true
host.cpu.vendor.id:
enabled: true
host.cpu.family:
enabled: true
host.cpu.model.id:
enabled: true
host.cpu.model.name:
enabled: true
host.cpu.stepping:
enabled: true
host.cpu.cache.l2.size:
enabled: true
transform:
error_mode: ignore
# コード関数名の適切な命名
trace_statements:
- context: span
conditions:
- attributes["code.namespace"] != nil
statements:
- set(attributes["resource.name"],
Concat([attributes["code.namespace"],
attributes["code.function"]], "#"))
# Kubernetes ホスト名の適切な設定
- context: resource
conditions:
- attributes["k8s.node.name"] != nil
statements:
- set (attributes["k8s.node.name"],
Concat([attributes["k8s.node.name"], "k8s-1"], "-"))
metric_statements:
- context: resource
conditions:
- attributes["k8s.node.name"] != nil
statements:
- set (attributes["k8s.node.name"],
Concat([attributes["k8s.node.name"], "k8s-1"], "-"))
log_statements:
- context: resource
conditions:
- attributes["k8s.node.name"] != nil
statements:
- set (attributes["k8s.node.name"],
Concat([attributes["k8s.node.name"], "k8s-1"], "-"))
attributes/sidekiq:
include:
match_type: strict
attributes:
- key: messaging.sidekiq.job_class
actions:
- key: resource.name
from_attribute: messaging.sidekiq.job_class
action: upsert
tail_sampling:
policies:
[
{
name: errors-policy,
type: status_code,
status_code: { status_codes: [ERROR] },
},
{
name: randomized-policy,
type: probabilistic,
probabilistic: { sampling_percentage: 0.1 },
},
]
connectors:
datadog/connector:
traces:
compute_stats_by_span_kind: true
exporters:
datadog:
api:
site: ${DD_SITE}
key: ${DD_API_KEY}
traces:
compute_stats_by_span_kind: true
trace_buffer: 500
service:
pipelines:
traces/all:
receivers: [otlp]
processors:
[
resource,
k8sattributes,
resourcedetection,
transform,
attributes/sidekiq,
batch,
]
exporters: [datadog/connector]
traces/sample:
receivers: [datadog/connector]
processors: [tail_sampling, batch]
exporters: [datadog]
metrics:
receivers: [datadog/connector, otlp]
processors:
[resource, k8sattributes, resourcedetection, transform, batch]
exporters: [datadog]
logs:
receivers: [otlp]
processors:
[
resource,
k8sattributes,
resourcedetection,
transform,
attributes/sidekiq,
batch,
]
exporters: [datadog]
最新の状態を維持する
Mastodon は通常、各リリースから 1~2 日以内に OpenTelemetry Collector をアップグレードしています。
「すべてが文書化されていて、破壊的変更もきちんと詳しく説明されています」と Tim は述べ、リリースノートの分かりやすさを高く評価しました。
頻繁なリリースでは破壊的変更が導入されることもありますが、チームはこれを健全で活発な開発の証と捉えています。 最新の状態を維持していれば問題ありません。
教訓と課題
この取り組みで最も困難だったのは、単純に始めることでした。 Collector のコンポーネントがどのように組み合わさるかを理解するには時間がかかりました。 特に、専任のオブザーバビリティスペシャリストがいないチームにとってはなおさらです。 最近では、最も大きな複雑さは transform プロセッサーの高度な使い方から生じています。 特に、バックエンド固有の命名要件に合わせてスパン属性を適応させる場合です。
transform:
error_mode: ignore
# コード関数名の適切な命名
trace_statements:
- context: span
conditions:
- attributes["code.namespace"] != nil
statements:
- set(attributes["resource.name"], Concat([attributes["code.namespace"],
attributes["code.function"]], "#"))
上記の transform プロセッサールールでは、resource.name(Datadog 固有の属性)を code.namespace#code.function の値に設定する条件を構成しています。
これを設定することで、スパンがバックエンドに到着した際に、定義した名前にマッピングできるようになりました。
その学習曲線にもかかわらず、全体的な体験は期待を上回るものでした。
「基本的に、やりたいことは何でもできます。期待を超えていました。全体的にとてもうまく動いています。」
その信頼性と柔軟性こそが、Mastodon が本番環境で OpenTelemetry Collector を使い続けている理由です。
小規模チームへのアドバイス
Mastodon の経験に基づいて、いくつかの教訓が際立っています。
- アーキテクチャをシンプルに保つ: 1 つの Collector で十分にまかなえる
- Kubernetes オペレーターに頼る: ライフサイクル管理に活用する
- サンプリングを使う: コストを制御する
- セマンティック規約に従う: 長期的なロックインを回避する
- 頻繁にアップグレードする: 破壊的変更の影響を軽減する
今後の展望
Mastodon のストーリーは、非常に小さなチームでも、大きな運用負担なしに、世界規模で OpenTelemetry Collector を本番環境で運用できることを示しています。
これはシリーズの最初のストーリーにすぎません。
今後の記事では、中規模および大規模な組織が OpenTelemetry Collector をどのようにデプロイ・運用し、サービス間の計装をどのように管理しているか、そしてスケールに応じてどのように課題と解決策が変化するかを探ります。
OpenTelemetry を本番環境で運用していて、自身の経験を共有したい方は、CNCF の #otel-devex Slack チャンネルに参加してください。 あなたのストーリーをお聞きし、OpenTelemetry の開発者体験をともに改善していきたいと考えています。