LLM 呼び出しの内側: OpenTelemetry による GenAI オブザーバビリティ
AI エージェントに単純な質問をしたら、回答までに 45 秒もかかった、ということを想像してみてください。 原因はモデルでしょうか。 それともツール呼び出しが遅かったのでしょうか。 あるいはリトライのループに陥っていたのでしょうか。 アプリケーションが LLM を呼び出すたびに、モデル呼び出し、ツール実行、トークンのやり取りといった一連の処理が裏側で起きています。 オブザーバビリティがなければ、原因は推測するしかありません。
OpenTelemetry の Generative AI 向けセマンティック規約 は、この内側を可視化します。 GenAI 操作の記録方法を標準化しており、呼び出されたモデル、入出力のトークン数、そして明示的に有効化した場合にはプロンプト、応答、ツール呼び出し、ツールの実行結果の中身までを記録します。
この記事では、以下を順に紹介します。
- LLM を活用したアプリケーションから GenAI のテレメトリーをエクスポートする。
- そのテレメトリーを受信して表示できるよう、オブザーバビリティツールを設定する。
- GenAI ビジュアライザーを使って、GenAI のトレース、メトリクス、イベントを探索する。
GenAI テレメトリーをエクスポートする
このチュートリアルでは、多くの開発者がすでにインストール済みであることから、テレメトリーを発生させるツールとして VS Code Copilot を使います。 ただし、多くのコーディングアシスタントが OpenTelemetry によるモニタリングをサポートしています。
- VS Code Copilot は、エージェントとのやり取りごとにトレース、メトリクス、イベントを出力します。
- OpenAI Codex は、API リクエスト、ツール呼び出し、セッションについて、構造化ログイベントと OTel メトリクスをエクスポートします。
- Claude Code は OTel でメトリクスとログイベントをエクスポートし、トレース対応はベータ版で提供されています。
すでに使っているツールをモニタリングするだけでなく、自分の GenAI アプリケーションに OpenTelemetry を組み込めば、LLM とのやり取りの様子を可視化できます。
テレメトリーエクスポートを設定する
テレメトリーをエクスポートするには、いくつかの設定が必要です。
VS Code Copilot の場合は、設定画面を開いて copilot otel で検索してください。
| 設定 | 説明 | 値 |
|---|---|---|
github.copilot.chat.otel.enabled | OTel の出力を有効にする | true |
github.copilot.chat.otel.captureContent | プロンプトと応答の内容を丸ごとキャプチャする | true |
github.copilot.chat.otel.otlpEndpoint | OTLP Collector のエンドポイント | "http://localhost:4318"(デフォルト値、変更不要) |
デフォルトでは、機密データが含まれる可能性があるため、プロンプトの内容やツール引数は GenAI テレメトリーに記録されません。 記録されるのは、モデル名、トークン数、所要時間といったメタデータだけです。 コンテンツのキャプチャを有効にすると、スパン属性にプロンプトメッセージ、システムプロンプト、ツールスキーマ、ツール引数、ツール実行結果が含まれるようになります。
GenAI テレメトリーを探索する
OTLP 互換のバックエンドであれば、どれでも GenAI テレメトリーを受信できます。 このチュートリアルでは、Aspire Dashboard を使います。 これは Docker コンテナとして提供される、無料でオープンソースのテレメトリービューワーです。 OTLP データを直接受け付け、トレースビューワー、メトリクスエクスプローラー、構造化ログページが組み込まれており、クラウドアカウントは必要ありません。 ローカルでの開発や GenAI ワークロードのデバッグに適しています。
利用を始めるには、以下の Docker コマンドを実行します。
docker run --rm -p 18888:18888 -p 4317:18889 -p 4318:18890 -d --name aspire-dashboard \
-e ASPIRE_DASHBOARD_UNSECURED_ALLOW_ANONYMOUS=true \
mcr.microsoft.com/dotnet/aspire-dashboard:latest
ダッシュボードは http://localhost:4318 に送信されたテレメトリーを収集し、http://localhost:18888 を開くと参照できます。
ダッシュボードはデフォルトで認証を要求します。
ローカル開発中に匿名アクセスを許可するには、-e ASPIRE_DASHBOARD_UNSECURED_ALLOW_ANONYMOUS=true を指定してください。
トレースを探索する
VS Code Copilot からの GenAI 操作が、これで記録され観測可能になりました。 VS Code で Copilot に何か質問してから、ダッシュボードの Traces ページを開いてください。 LLM とのやり取りごとにエントリーが並んでいるのが分かります。
トレースを選択すると、スパンツリーが表示されます。
最上位の invoke_agent スパンの下に、各 LLM 呼び出しごとの chat 子スパンと、各ツール実行ごとの execute_tool スパンが配置されています。
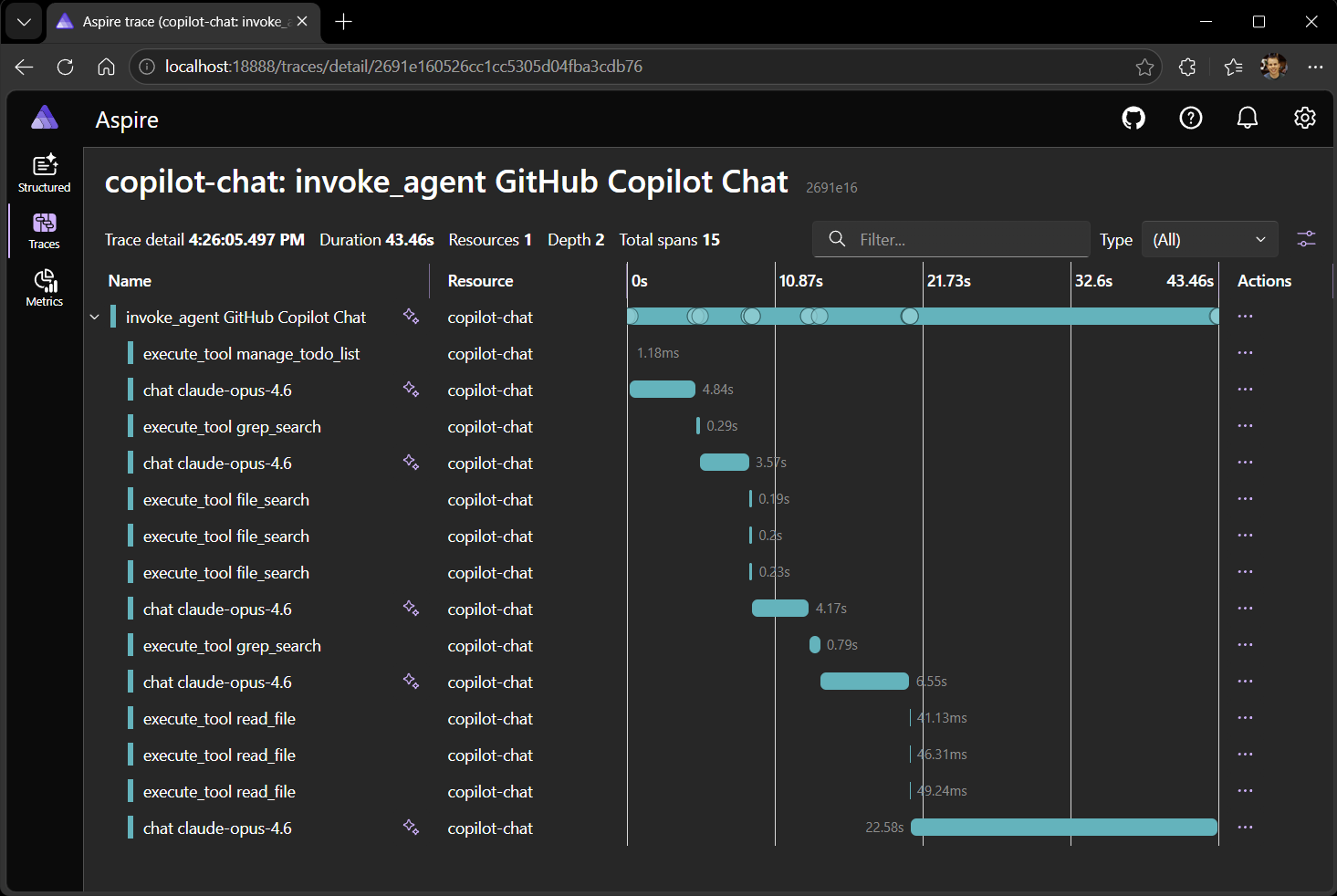
スパンの詳細には、GenAI セマンティック規約の属性が含まれます。
gen_ai.request.model— 使用されたモデル(例:gpt-4o)。gen_ai.usage.input_tokensとgen_ai.usage.output_tokens— 各 LLM 呼び出しのトークン数。gen_ai.response.finish_reasons— モデルが生成を停止した理由(例:stopやtool_calls)。
アプリケーションでコンテンツの記録を有効にしている場合は、メッセージやツール呼び出しは gen_ai.system_instructions、gen_ai.input.messages、gen_ai.output.messages といった構造化スパン属性として記録されます。
これらの内容はデバッグの際に有用ですが、属性は大きくなりがちで、多くのオブザーバビリティプラットフォームでは生の JSON として描画されるため、読みづらくなりがちです。
オブザーバビリティツールの中には、GenAI テレメトリー表示に特化した UI を備えるものがあります。 ここでは、これらの属性を解析してチャット形式のビューでシステムプロンプト、ユーザーメッセージ、アシスタント応答、ツール呼び出しの引数と結果を表示する、GenAI テレメトリービジュアライザー を使います。
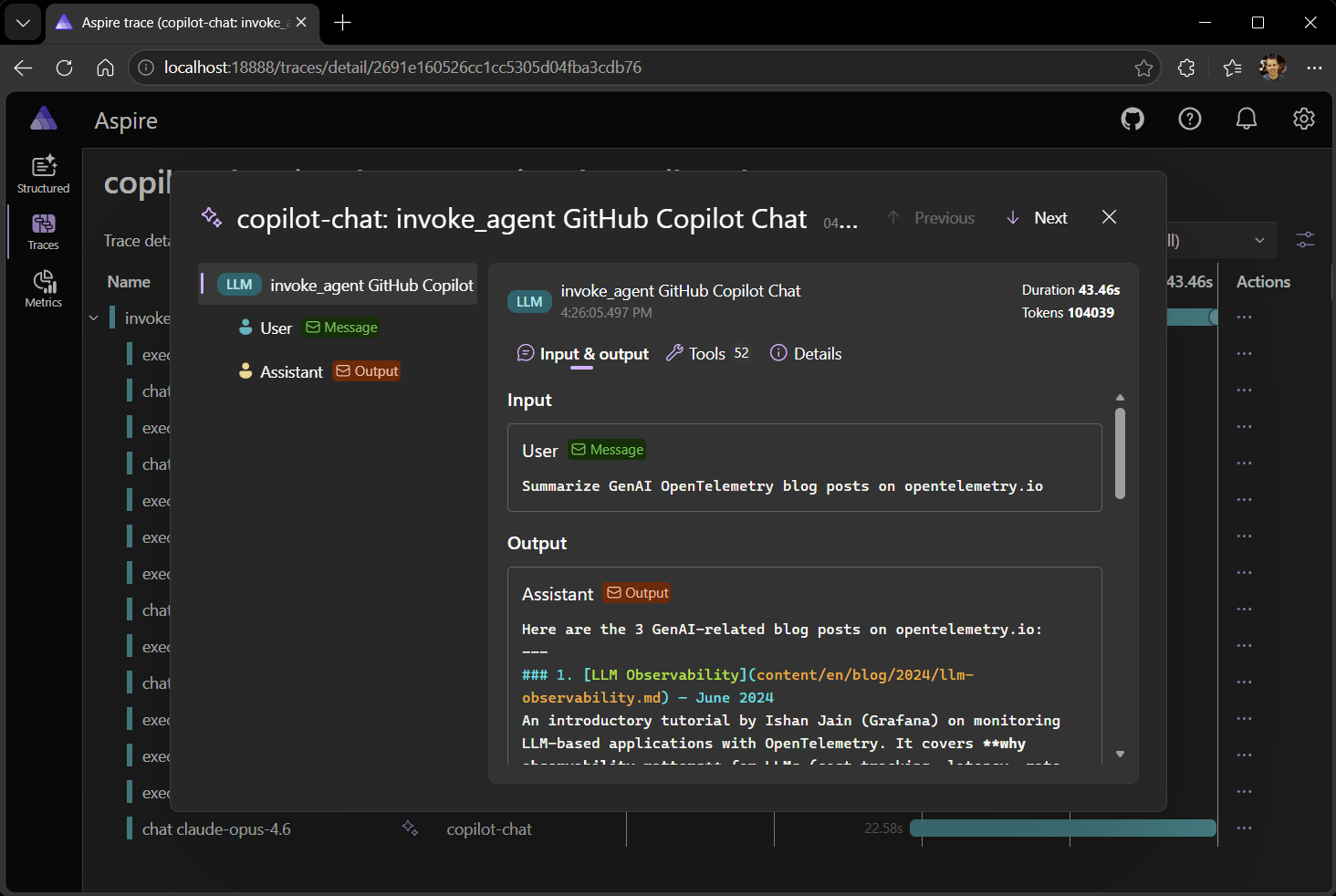
これで、LLM の使われ方を推測したり、生の JSON を掘り起こしたりする必要はなくなります。 GenAI テレメトリーがあれば、すべてのプロンプト、応答、ツール呼び出しを一目で見渡せます。
メトリクスを探索する
Metrics ページに移動し、copilot-chat サービスを選択してください。
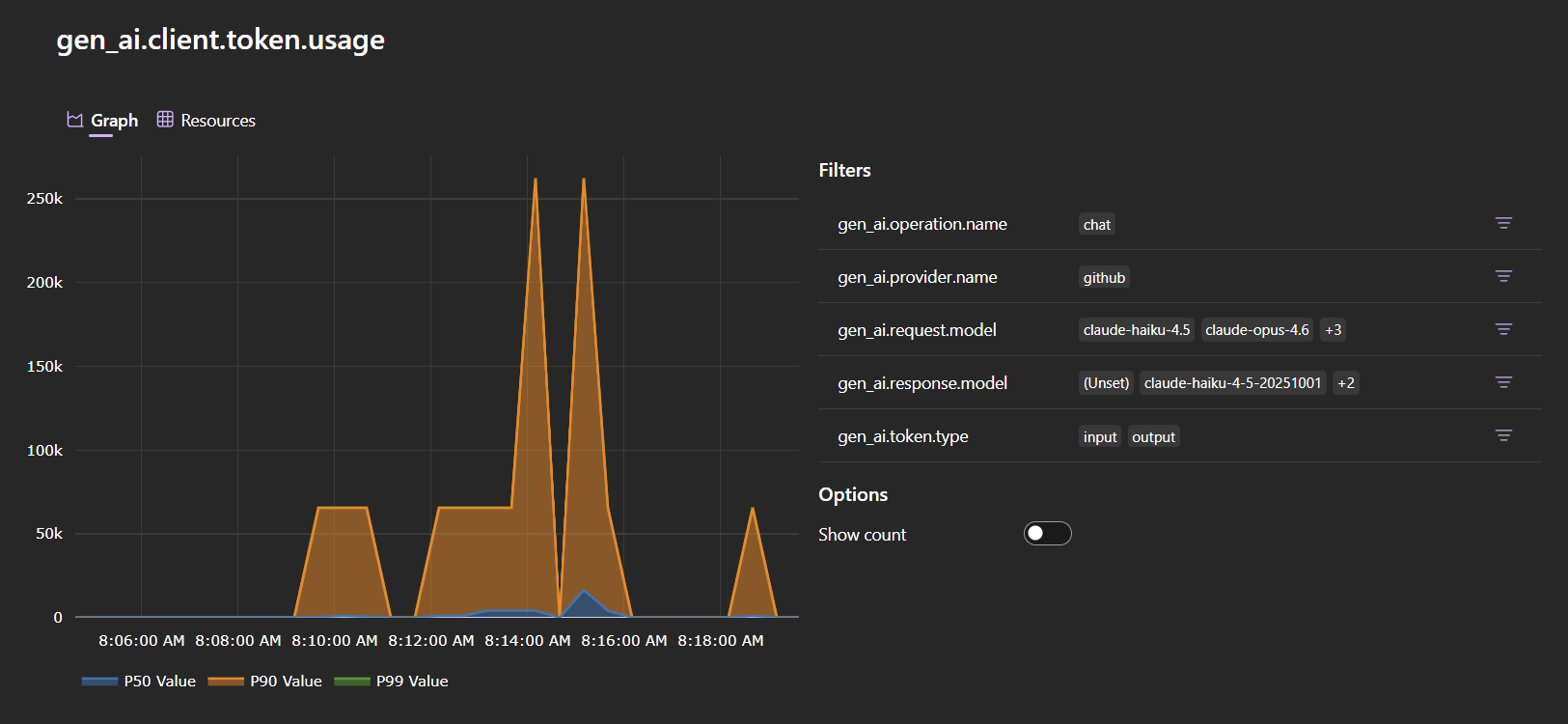
GenAI メトリクスは gen_ai という接頭辞でまとめられています。
gen_ai.client.operation.duration— LLM 呼び出しのレイテンシーのヒストグラム。gen_ai.request.modelでフィルタするとモデル間で比較できます。gen_ai.client.token.usage— トークン消費量のヒストグラム。gen_ai.token.typeでフィルタするとinputとoutputのトークンを分けて見られます。
これらのメトリクスがあれば、リクエストあたりのコストの見積もり、本番投入前にトークンを大量に消費するプロンプトの発見、レイテンシー悪化の検出、モデルやエージェントをまたいだ利用パターンのモニタリングが可能になります。
このデモのその先へ
GenAI のセマンティック規約はすでに実環境で使われており、いまも活発に開発が進んでいます。 実利用からのフィードバックは、次に何を標準化するかに直接影響します。
- 自分のアプリケーションで GenAI 計装を試して、Issue を報告してください。
- GenAI Semantic Conventions and Instrumentation SIG のディスカッションに参加してください。